Cognitive Testing Is Getting Faster and Better
Quick Links
If Jason Hassenstab has his way, an app that pings trial participants to take quick cognitive tests on their own cell phones will boost the reliability of data in future prevention studies. Hassenstab works at Washington University, St. Louis, and presented this work at the Clinical Trials on Alzheimer’s Disease conference, held November 1–4 in Boston. By prompting people to take tests several times daily over the course of a week and averaging results, the app accounts for hour-to-hour and day-to-day variation within a given person’s performance. This can greatly improve reproducibility in repeated cognitive assessments. In a separate study, Dorene Rentz of Brigham and Women’s Hospital, Boston, ran a digitized version of an old clock-drawing test through its paces. She found that the use of a digital pen revealed subtle cognitive changes that go undetected in the pen-and-paper version of the task. Importantly, scores on digital clock drawing tracked with biomarkers of amyloid and tau deposition, and neuronal metabolism.
- Short, frequent bursts of cognitive testing make results more reliable.
- A smartphone app moves testing from a clinical site to people’s day-to-day lives.
- Digital pen shows there’s more to clock drawing than meets the eye.
Variability in cognitive testing is a huge problem. Its source is no mystery: During clinic visits, people may be tired from traveling, fighting a cold, or coming off a bad night’s sleep. They are anxious about being tested by someone in a white coat, and about coming face-to-face with their cognitive decline. They take back-to-back tests, in a single, long sitting. Many participants dread these extended test sessions. One year later, they return for more of the same.
With this model, replication is not assured. In fact, a “bad day” performance at visit 1 followed by a “good day” performance at visit 2 can make it seem as if the patient’s cognition improved when, in fact, it slipped.

Roller Coaster.
Day-to-day variability in testing can overshadow a true change in cognitive function. [Courtesy of Jason Hassenstab.]
For some commonly used cognitive measures, test-retest correlations—when the same person takes the test at two different times—are as low as 0.5. In the Dominantly Inherited Alzheimer Network (DIAN) Observational Study, Hassenstab showed, it can be even worse, with some young, healthy participants showing test-retest correlations in the 0.4–0.5 range. “We would never accept this low test-retest reliability in a biomarker,” Hassenstab said. To overcome this problem and still achieve statistical power, clinical trials must enroll large numbers of people. Alas, large trials are impossible in rare genetic populations, and wasteful in late-onset AD populations.
Burst testing seeks to reduce this variability by testing people briefly, for a few minutes, but repeatedly, at random times in the course of their normal daily life. A “burst” consists of seven days of consecutive testing, which is collapsed into one “visit” by averaging performance scores across the week. Burst testing can achieve test-retest correlations greater than 0.9 on some cognitive measures (Sliwinski et al., 2018). “It’s not a new idea, but our focus is on developing this method for prevention trials. I’m interested in making the data as reliable as possible,” said Hassenstab.

Grid Game.
In a rapid, mobile test of spatial working memory, the user remembers and reports where three items are on a grid, after completing an unrelated task. [Courtesy of Jason Hassenstab.]
Hassenstab developed the Ambulatory Research in Cognition (ARC) mobile app for testing cognition in preclinical AD. On their own cell phones, participants receive prompts to take a brief test four times a day for a week. In just a few minutes, they click through three tasks, which evaluate working spatial memory, processing speed, and associative memory.
At CTAD, Hassenstab first showed that scores on the phone test and pen-and-pencil tests correlated. Then he described results of testing ARC in real life in three different cohorts of cognitively normal adults. One included 10 members of the DIAN cohort, five mutation carriers and five noncarriers, whose average age was 38. In addition, he enrolled 17 older subjects from WashU’s own ADRC cohort, whose average age was 74. Both cohorts showed good compliance, completing an average of 21 to 22 sessions out of 28 per week. A community sample, recruited via social media, was a little less dutiful: The 85 participants, mostly women and with an average age of 38, completed 18 to 19 assessments per week.
With the smartphone tests, Hassenstab saw reproducibility climb as the number of sessions increased, so that after seven days, the test-retest reliability was near to, or even exceeded, his preset goal of 0.9 for each domain. Test scores varied over the seven days, but averaging the scores smoothed out a person’s ups and downs. “Our reliability is now very high. I am really happy about how this is panning out this far,” Hassenstab said.
Putting the test on personal phones, rather than providing a separate device to participants, is important to Hassenstab. “We want people to be familiar with their device when they do the testing, so it feels less like a separate task outside their daily life, and more like part of the natural use of their phone,” he explained. But bring-your-own-device has its own vagaries: Different phone models vary in important parameters, such as how quickly they display an image, and how fast they register a screen tap. iPhones are manageable, Hassenstab says, because there are but a few models, with consistent specs and operating systems. However, android phones are another story, with more than 5,000 devices whose software and specs vary widely. Inconveniently, some people change phones midway through studies.
Rhino Tap. A homemade robot makes 5,000 taps to assess the response latency of smartphones used for mobile cognitive assessments. Why put a three-D printed rhino head on the robot? "Oh, just because we could. It's for fun," said its maker. [Courtesy of Jason Hassenstab.]
Hassenstab’s group is developing rigorous validation protocols for phones. One accounts for tap latency—the time it takes for the phone’s processor to register a screen tap. Variations here can skew measures of response time, which form part of a participant's processing speed. Hassenstab’s team built a robot that taps a phone 5,000 times to determine the device’s tap latency; they then use that data as a covariate in their analysis to account for differences in phones. For iPhones, the latency is around 50 milliseconds, but for other phones the values vary a lot, Hassenstab said. When the response times that differentiate normal and preclinical AD might be just 100–200 milliseconds, knowing a phone’s lag time, and adjusting for it, matters.
Age matters. “In DIAN-TU, issues are minor because our participants are younger; they have phones and know how to use them. They easily download the app and get running,” Hassenstab said. In older cohorts, he finds more variability in people’s experience and comfort levels with the app. “This is early days of doing this with older people,” he says. “Many use smartphones, but many don’t. We find if we give them a phone, and sit with them and get the app working, mostly they are delighted to use it.”

Data Capture.
A digital pen with integrated camera and processor continuously tallies starts, stops, and stroke shapes during drawing, providing a wealth of information for analysis. [Courtesy of Dorene Rentz.]
The open-source ARC code will be freely available to anyone in the research community interested in build their own app. Hassenstab expects to release it in January 2018.
Yet another time-honored cognitive test is going digital. Rentz at Brigham and Women’s reported on DCTClock, an upgrade on the traditional pen-and-paper clock-drawing test that is being developed by Digital Cognition Technologies, a startup in Waltham, Massachusetts (Dec 2012 news).
Clock drawing is a simple and common screen for dementia. Clinicians ask people to draw the face of an analog clock showing a specific time, often 10 minutes past 11. Errors in the finished drawing spark further evaluation.
A physician looking at the paper sketch analyzes only the final product, whereas the digital version also captures the process. A digitizing pen records time and location continuously during drawing, detecting not just what people draw, but also when they hesitate, or stop and think, and how they organize the task. All told, the accompanying software analyzes 700 features of the drawing process, and compares the output to a database of more than 4,500 healthy and pathological tests to generate an objective score of cognitive function.
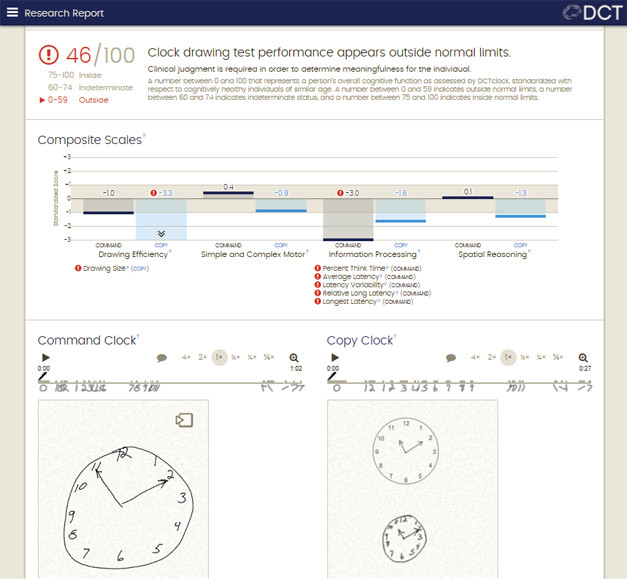
Big Reveal? Automated analysis detects subtle cognitive problems, even when the drawings look acceptable. The digital pen picks up deficits in drawing efficiency and information processing. It renders a composite score and flags if it’s outside the normal range. [Courtesy of Allison Byers, Digital Cognition Technologies.]
To ask if the digitized pen could pick out subtle cognitive impairment, Rentz compared scores on this test to results of traditional cognitive tests and to levels of AD biomarkers in 105 clinically normal older adults, some from the community and some in the Harvard Aging Brain Study. Everyone took a battery of traditional cognitive tests, and the 63 HABS participants also had amyloid, FDG and tau PET scans. Rentz found that digital-clock test scores correlated most closely with pen-and-paper tests of executive functioning and processing speed. People with subtle cognitive impairment, as defined by a performance more than 0.5 standard deviations below the norm on the Preclinical Alzheimer’s Cognition Composite, or PACC, scored significantly lower on the digital-clock test than people without any cognitive impairment.
Digital-clock scores also correlated with biomarkers. Worse overall performance on the test was associated with greater amyloid deposition, greater parietal glucose hypometabolism, and with a trend toward higher entorhinal and inferior temporal tau accumulation. The investigators concluded that the digital pen may offer a quick and sensitive measurement of cognitive change in preclinical AD, and of change over time in clinical trials.
The projects featured above are but two examples of a much larger number of efforts occurring simultaneously throughout the field. In them, biostatisticians are looking for how they might be able to extract a much richer data set for analysis from the cognitive test sessions researchers demand of study participants. One other example is the work of Howard Mackey at Genentech, who is collaborating with Ron Thomas at University of California, San Diego, and colleagues from the Alzheimer’s Prevention Initiative API. Mackey reported at CTAD that if AD trials were to use rate of decline as a summary measure—not change from baseline, as they currently do—then they would be able to incorporate a larger fraction of the data collected at points in between a trial’s baseline and its final visit.
A related point emphasized by numerous biostatisticians, including Mackey, WashU’s Andrew Aschenbrenner, and Suzanne Hendrix of Pentara Corporation, is that participants should be tested much more frequently than once every six months, and statistical models should be refined to optimize data from frequent measures. All of this work serves the goal of boosting the power of natural history and therapeutic studies.—Pat McCaffrey and Gabrielle Strobel
References
Paper Citations
- Sliwinski MJ, Mogle JA, Hyun J, Munoz E, Smyth JM, Lipton RB. Reliability and Validity of Ambulatory Cognitive Assessments. Assessment. 2018 Jan;25(1):14-30. Epub 2016 Apr 15 PubMed.
Further Reading
No Available Further Reading
Annotate
To make an annotation you must Login or Register.
Comments
No Available Comments
Make a Comment
To make a comment you must login or register.